
Cross-platform offline speech recognition for Unreal Engine. Powered by Whisper AI - convert speech to text entirely on-device, across all platforms, with no internet connection required.
Built on the whisper.cpp implementation of OpenAI's Whisper model - state-of-the-art accuracy running entirely on-device, with no data sent to external servers.
Process audio in real-time as it's captured - ideal for live voice commands and interactive applications.
Process complete audio files or buffers in a single pass for maximum transcription accuracy.
Automatic language detection or explicit selection. Translation to English is also supported.
Vulkan-based GPU acceleration on Windows for significantly faster recognition. CPU + intrinsics on all other platforms.
Audio is processed entirely on-device using the Whisper model. No internet connection, no external API calls, no data leaving the device.
Microphone capture, audio files, or any PCM source - including Runtime Audio Importer
Whisper model runs locally - streaming or full-buffer, with optional VAD pre-filtering
Text output with segment timestamps, language detection result, and confidence data
Bind to result delegates in Blueprint or C++ and act on recognized text immediately
Five model sizes let you balance transcription accuracy against memory footprint and processing speed for your target platform.
| Model | Size | Languages | Best for |
|---|---|---|---|
| Tiny | 75 MB | Multi / EN | Mobile, Quest |
| Base | 142 MB | Multi / EN | Low-end devices |
| Small | 466 MB | Multi / EN | Balanced |
| Medium | 1.5 GB | Multi / EN | High accuracy |
| Large | 3 GB | Multi | Maximum accuracy |
Quantized variants also available for reduced memory usage. Custom models supported.
Recognizes speech in 95+ languages with automatic detection, or specify the language explicitly for best performance. Translation to English is also supported.
Fine-grained control over recognition parameters, performance tuning, and output filtering - all accessible from Blueprints or C++.
Configure thread count, step size, beam size, audio context size, and no-context / single-segment modes. Separate defaults for streaming and non-streaming modes.
Enable speed-up mode, select GPU device ID for multi-GPU systems, and adjust audio context size to trade accuracy for speed on constrained hardware.
Provide an initial prompt to guide transcription style. Suppress blank segments and non-speech tokens to keep output clean and structured.
Combine with Runtime Audio Importer's Voice Activity Detection to feed only speech segments into the recognizer - improving accuracy and reducing wasted compute.
Translate recognized speech from any supported language directly to English in a single pass - no separate translation step required.
No internet connection required, no API keys, no data leaving the device. Suitable for privacy-sensitive applications and air-gapped environments.
Blueprint Example - Streaming recognition with Voice Activity Detection
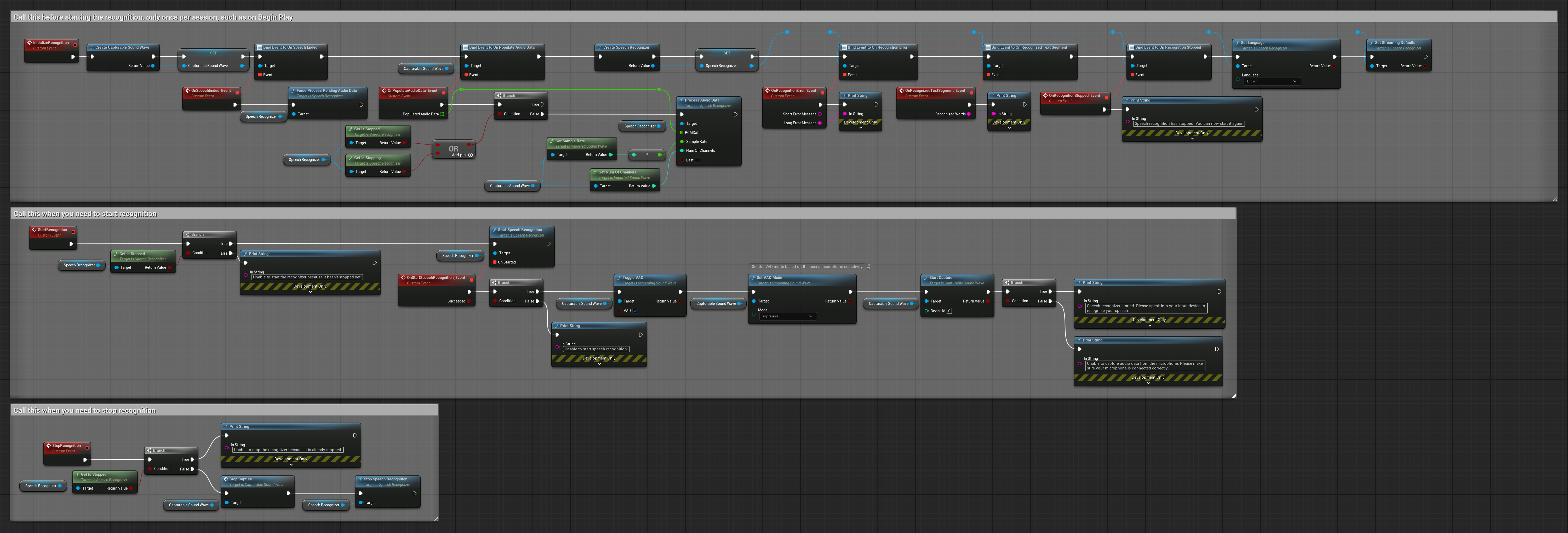
The same Blueprint and C++ API works across every platform Unreal Engine supports - from desktop to mobile to consoles.
GPU acceleration via Vulkan on Windows. CPU + intrinsics acceleration on all other platforms including Android, iOS, and consoles.
Runtime Speech Recognizer fits naturally into the Georgy Dev plugin suite - combine it with audio capture, TTS, and AI chat to build complete voice-driven character pipelines.
Microphone capture with Voice Activity Detection - feed clean speech segments directly to the recognizer.
Learn moreReal-time lip sync for MetaHuman and custom characters - animate responses to recognized speech.
Learn moreFully offline speech synthesis - close the voice loop by speaking responses back to the user.
Learn moreProcess recognized speech with various AI providers (OpenAI, Claude, DeepSeek, Gemini, Grok, Ollama, ElevenLabs, Google Cloud, and Azure) to power intelligent conversational NPCs.
Learn moreGenerate dialogue with on-device LLMs offline, then drive lip sync from the synthesized speech for fully offline character interactions.
Learn moreComprehensive documentation covers streaming and non-streaming workflows, model selection, language configuration, VAD integration, and platform-specific guidance.
Step-by-step guides for all features, with Blueprint and C++ examples
Complete walkthrough covering setup, streaming recognition, and VAD integration
Active Discord community with developer support
Tailored integration or feature development - solutions@georgy.dev
Available on Fab for UE 4.27 – 5.8. Includes all model sizes, full documentation, and a demo project.